Last updated on August 9th, 2024 at 09:56 am
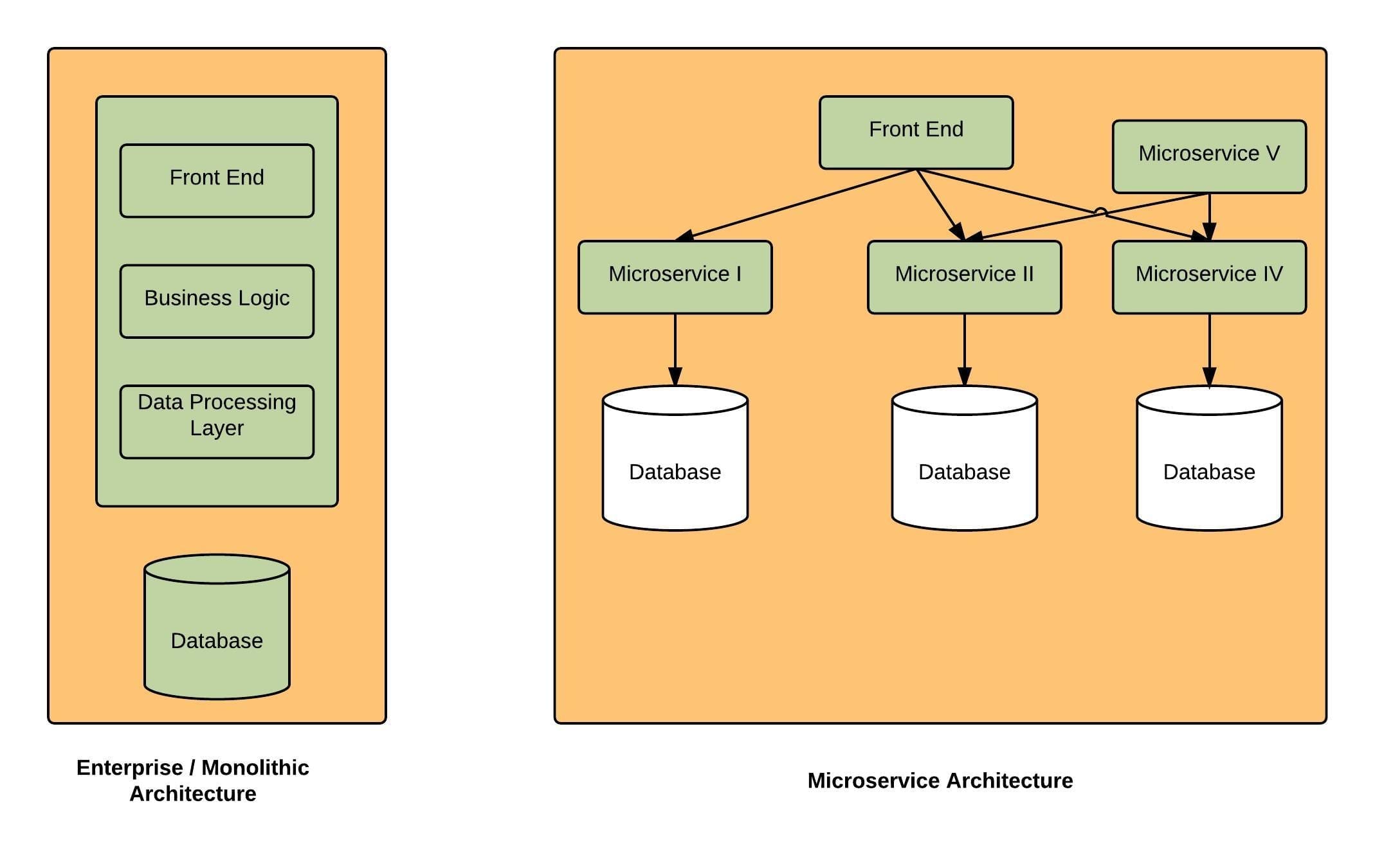
Microservices is the new buzz word. It refers to smaller and more manageable services that serves a specific use case.
They are the exact opposite of a mololytictic application where you have a self contained application that would carry out any and all requests that come to it.
They are also most often built by smaller team that own, provision the necessary environments, design, develop, test and deploy them. This way the team has full responsibility and takes onus in case it is in a bad state or when the particular service very popular.
Microservices
One of the key identifiers of a microservice is that they are self-sufficient services with its own data store and is modeled based on the current use cases of the application.
Fundamental Needs & Characteristics of a Microservice
Data Storage:
When designing Microservices, their Data storage needs and the features requirements need to be clear. It is normally advisable to have independent datastores for each microservice. If multiple apps are trying to CRUD the same data store it would affect the performance of the service.
It does at times get tricky designing microservice applications with its own independent datastore. Because in real life the same data most often needs to be accessed by several different apps who need this data. In a microservice world this is done via the App/ microservice.
When creating microservices with its own data stores its imperative to avoid data replication as it causes inconsistencies in data which in turn translates to inconsistent user experience. Eg you see a certain price when you search but when you add it to the cart the price is different because the checkout api is using its own data store.
Consistency & API agreements:
Contracts should be definitions of what the request should contain and what the response should be.
It is important that contracts are not broken when changes are made. This way one does not need have dependant application to need to run tests for every release.
When there is an absolute need change the required parameters of a request or response one can create a V2 of the API and leave it up to the clients who would then move to the new version of the api if they need the new functionality. Having various versions and maintaining them might take some effort but the onus is on the calling party to use the new version.
Interdependent Services:
Avoid building interdependent services, services should be loosely coupled. If you are building heavily interdependent services then the fundamental breakdown of what you consider a microservice may have been missed.
The issue with building interdependent services is that if one service fails it should not inversely affect the secondary service.
Speed of Deployment / Agile Teams:
Scrum
Quick test and release culture. As the risk is relatively low and isolated in deploying smaller changes. Since each microservice have their own automated regression tests it’s quicker to develop test and deploy and not to mention that each of these deployments pose a very small risk as the change is small.
Dev & QA are also in control as they have intimate knowledge of what could go wrong and in the event something does go wrong they most likely know what caused the issue.
Once changes are made and has been tested it can be deployed in a moments notice, it does not need signoff from the 10 other downstream teams as long as the API contracts are met.
One of the key tenants of microservices are that you do not need lockstep releases in general. This brings about the true speed and agility of agile teams !
Monitoring & Fault Tolerance:
For effectively using microservices you need to have efficient monitoring. While building microservices you need to manager your connection pools to downstream apps effectively and efficiently by time out sooner by Bulkheading. Bulkheading is the process of ensuring that downstream systems do not have a cascading effect.
One could also set up Hystrix. Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems, services and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable. This way you avoid cascading of dependent systems.
Check out my blog on building resilience microservices.
Fast Failure:
(As mentioned above). Slow failure keep thread pools open. and causes dependent apps to queue more requests and more requests and thereby cause a more cascading effect.
Efficient Logging For Quick Troubleshooting:
Microservices need good logging to diagnose failure quickly and efficiently. It would also be necessary to have Correlation ID to track your request with an ID or GUID as they make it through the various micro services. That way one can exactly pinpoint where the issue is and follow the data.
Advantages of Microservices
Maintainability:
The advantage of building smaller services that are loosely coupled with bounded contexts. They are ideally not more than 100 lines of code and are responsible for one function or a feature. By making the service independent and small make them easily maintainable.
Learnability / Ramp Up:
Microservices are relatively easy to learn for new developers. When services are small and learn the ramp-up time is quick. This also allows devs to become proficient at new services sooner.
Ease of Use:
Each service of the microservice architecture could be written in any language since they all finally communicate using the same protocol.
Independent:
Also, microservices are self-contained and independent, in an event of failure of a specific microservice then only that one service is affected. Microservices provide improved fault tolerance and isolation.
A/B Testing:
Microservices lends itself to A/B testing, where you need a percentage of your traffic hitting a certain code path and to analyze and understand how customers are reacting to the change. This is easily possible as the content of the response of the API may change while the API parameters would not.
Doker or Ideally you are looking at one service per host:
Hosting multiple microservices on a single VM becomes problematic. Sharing VMs make it harder to restart your hosts, clear their cache, work on memory leaks, garbage collection without affecting other apps. However, more services mean more boxes which means more network connections more load balancers more hard disks. All of which now have increased chances of failure as you now have more distributed hardware. Also, this means you incur more cost however insignificant the cost of a VM might be.
Possible Disadvantages
Though the below-listed items are not entirely disadvantages they are more things to be aware of while building microservice architecture thorough testing needs to be done so the upstream and downstream API contracts are not changed. Having a good regression test and a stable test environment with quick running regression tests are needed.
While building Microservice it is important to realize that it’s not a one-off service that you are building but it’s the whole ecosystem of smaller services. There are certain needs of an ecosystem which I have detailed above, a microservice needs several checks and balances in place.
Team Ownership:
One of the unfortunate disadvantages of a microservice is that these microservices grow and are owned by multiple teams. It becomes increasingly difficult to build a feature, as APIs and the underlying data are owned by different teams or groups. This brings about a lot of cross-team collaboration which at times can make the whole processing of getting a feature out slow.
It is important to cross-train your team to learn and support all the microservices your team owns. This could be counterintuitive as you cannot have 20 people know the 100 microservices your team owns, but you get the point.
Though up and downstream systems should ideally not be affected when changes are made, at times they are this blocks other teams. As teams mature using microservices
Hardware:
Although hardware costs are generally low, they add up when you use Microservices. N monolithic application instances with NxM services instances. If each service runs in its own JVM (or equivalent), which is usually necessary to isolate the instances, then there is the overhead of M times as many JVM runtimes. Moreover, if each service runs on its own VM (e.g. EC2 instance), as is the case at Netflix, the overhead is even higher.- Exponential cost of hardware and multiple pre-prod env + horizontal scaling of theses ever growing microservice application in numbers. It becomes a little tricky when multiple apps would like to read and write to the same data store. That’s why the data needs to be modeled by the use case you are trying to support.