

Last updated on September 27th, 2022 at 12:26 am
Podcast: Play in new window | Download | Embed
A very interesting TPM Podcast with Vidya Vrat Agarwal on Microservices. We talk about large enterprises moving from a monolithic application patterns on to microservices what that entails. We go on to talk about various microservices best practices.
TPM Podcast with Vidya Vrat Agarwal on Microservices
This has been split into three eposodes:-
- Part I: Lives here.
- Part II: Lives here.
- Part III: Lives here.
Vidya’s LinkedIn Profile – https://www.linkedin.com/in/vidyavrat/
Also, read my previous post on microservices here – https://www.mariogerard.com/microservices/
We talk about :-
- What is a microservice?
- Advantages of microservices
- Monolithic applications vs microservices ?
- Why is there is renewed uptick in organizations using Microservices ?
- Pain points of microservices
- How do you break down monolithic applications into microservices
- Microservices Advanced Topics
Vidya’s Interesting LinkedIn Posts
Thank you ! Hope you enjoed it !
————****************———–
Vidya’s Linkedin Post (Extract)
Abstract
The microservices architecture style is an evolution of the Monolith SOA (Service Oriented Architecture) architecture style. The difference between the SOA and microservice approach is how these are being developed and operationalized. With every new technology addition, our responsibility also increases to be abreast of pros-and-cons the new member has, and the pain points it is designed to solve.
Monolith
Think of any MVC pattern-based API codebase, where all your controllers and POJOs (Plain Old Java Objects) or POCOs (Plain Old C# Objects) were developed, build and deployed as a single unit, and for almost all the times a single data store was used for the enterprise. I.e. One database is housing all the tables for various responsibilities, for example, Customer, Payment, Order, Inventory, Shipping, Billing, etc. as shown in the logical architecture diagram below. I.e. all the various responsibilities are together.
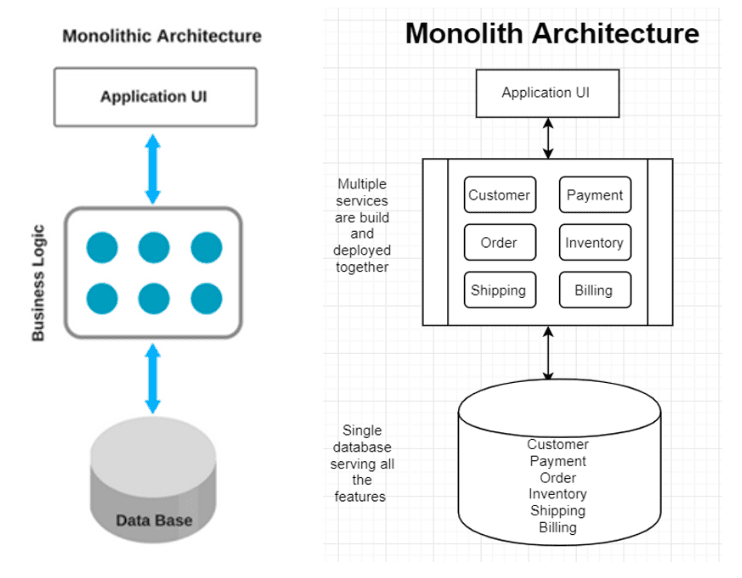
Monolith Pros:
• Less Cross-cutting Concerns: Being monolith and having all the responsibilities together, single or few implementations can cover all the major cross-cutting concerns such as security, logging.
• Less Operational Overhead: Having one large monolith application means there’s only one application you need to set up logging, monitoring, testing for. It’s also generally less complex to deploy, scale, secure and operationalize.
• Performance: There can also be performance advantages since shared-memory access is faster than inter-process communication (IPC).
Monolith Cons:
• Tightly Coupled: Monolithic app services tend to get tightly coupled and entangled as the application evolves, making it difficult to isolate services for purposes such as independent scaling or code maintainability.
• Harder to Understand: Due to many dependencies, monolithic architecture easily become harder to understand.
• Deploy all or none: When a new change needs to be pushed, all the services need to be deployed. I.e. if something changed in OrderController and you want to proceed with deployment, all other controllers and code will be deployed unwantedly.
• Scale all or none: Scale up/out/down, it’s for entire functionality.
Microservice
Gartner defines a “Microservice as a small autonomous, tightly scoped, loosely coupled, strongly encapsulated, independently deployable, and independently scalable application component. “ Microservice has a key role to play in distributed system architecture, and it has brought a fresh perspective.
Unlike monolith, a microservice strictly follows the Single Responsibility Principle (SRP) due to being tightly scoped around the business capability/domain for example Payment. Think of an MVC pattern-based API codebase where a controller and POJOs (Plain Old Java Objects) or POCOs (Plain Old C# Objects) were developed, build and deployed for just one single responsibility i.e. business capability. This microservice architecture will then lead to having many such projects and each business capability having its own database.
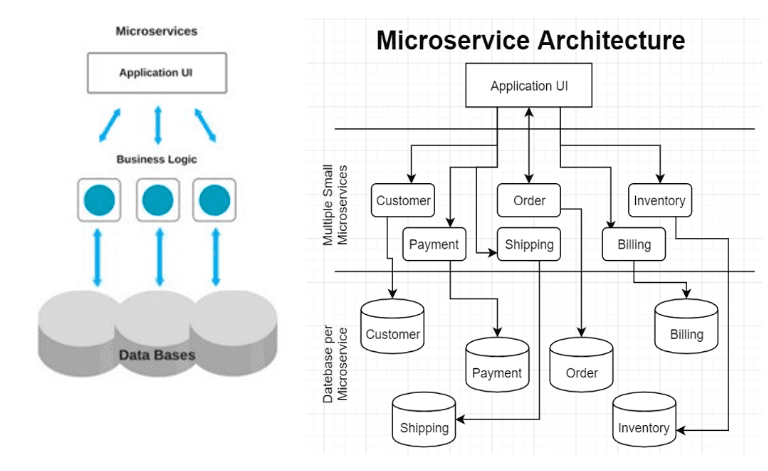
Micro service Architecture
Microservice Pros:
- Easier Deployments: Monolith was deploying all or none. Microservice is a small service, the dev team has complete control on what needs to be deployed and leave another feature’s code untouched. I.e. if changes made in Payment service, only payment can be deployed. This was not possible with a monolith.
- Scalability: Being a small tightly scoped service design, it gives freedom and flexibility to scale whichever service you want. For example, if needed only Payment can be scaled up/down/out.
- Easier maintainability: Each microservice service is autonomous and so being small service it’s much easier to maintain than a monolith.
- Problem isolation: Each service has its own codebase and deployed in its own space. Hence, any problem with self or other services remains completely isolated.
- Single Responsibility: Single Responsibility Principle is at the core of microservice design. This drives all other goodness microservice architecture offers.
- Separation of Concern: Microservices architecture leads towards building tightly scoped services with distinct features having zero overlaps with other functions.
- Deep domain knowledge: Microservice encourages the product mindset and leads towards establishing deep domain knowledge with “you build it, you run it” mantra.
Microservice Cons:
- Cultural Changes: It requires a cultural shift and organizational alignment to adapt microservice architecture, and the organization will require a mature agile and DevOps culture. With a microservices based application, service team needs to be enabled to manage the entire lifecycle of a service. Read my article on STOSA (Single Team Owned Service Architecture)
- More Expensive: Microservice architecture leads to growing costs, as there are multiple services. Services will need to communicate with each other, resulting in a lot of remote calls. These remote calls result in higher costs associated with network latency and processing than with traditional monolith architecture.
- Complexity: Microservices architecture by nature has increased complexity over a monolith architecture. The complexity of a microservices-based application is directly correlated with the number of services involved, and a number of databases.
- Less Productivity: Microservice architecture is complex. Increased complexity impacts productivity and it starts falling. Microservice development team usually requires more time to collaborate, test, deploy and operationalize the service which certainly requires more time.
Summary
Microservice and monolith architecture, both have their pros and cons. Microservice architecture is not a silver bullet, but teams which aspire to be digitally transformed and writing services with a product mindset, microservice architecture is certainly worth consideration.
Podcast Transcript
Hello, and welcome to the TPM podcast with your host, Mario Gerard. This is part three of three of the podcast on microservices recorded with Vidya Agarwal. If you haven’t listened to part one and two, I’d highly recommend you start there.
Mario Gerard: Advanced microservice topics like timeout patterns, retry patterns, and so on. So let’s start with the timeout patterns. Especially when there are upstream and downstream microservices, which are kind of interdependent. We spoke about synchronous and asynchronous type of communication. How does timeout patterns come into this?
Vidya Agarwal: So with microservices, what happens even with any service you’re building, I think these patterns are applicable to any architecture, but there are few which we will talk down the line, which are very specific to Microservices. Then I will call it out. I think timeout is applicable to any sort of service architecture you have, whether you have SOA, service oriented architecture, also known as monolith, or you are having microservice architecture. Whenever I’m making the call to any backend systems, whether I’m a consumer or I am an API consumer of another backend API, you know, API talk to API, sometimes UI talk to API and all these different integration patterns are out there.
The thing is timeout pattern plays the key role that I need to know what is my threshold and how long I’m going to wait for response to come back. Having said that you cannot indefinitely wait for your API to respond or your backend to respond. That threshold is usually decided by the SLAs. The SLA you will find when you have a thinking of owning your dependencies. Let’s say I am dependent on my billing domain or my payment domain. I need to understand their SLA, that if I am sending you a visa credit card, what is your SLA to process it?
Mario Gerard: And generally what’s the time.
Vidya Agarwal: So in T-Mobile also and many other organizations, industry standard in today’s two second rule, two second rule means end to end on UI I should see payment process. Thank you. Green check mark. All this good stuff on UI within two seconds. Having said that you need maybe half a second from the backend to get that information back, then another half a second, to call it massage, scrub if you are doing a scatter and gather and aggregate [02:36 inaudible] as I talked about, and then bring it back to the UI, then UI will take a few seconds, you know, a few milliseconds to [02:44 inaudible] scrub and map it back based on the swagger contracts define it, then show it to the customer. But many times it does not happen. So why does not happen? Maybe services running slow.
They have a hiccup on the server. However, all these, when you start owning your dependencies, you also know they’re monitoring things, how do you monitor? What is your SLA? How fast will you respond? What does your dependency system look like? How does your replication look like? Do you have any duplicacy available and all these things you will get to know. So in that case, if for whatever reason, I’m not getting a response back. And I assume that backend tried enough from their side, then I’m going to time out. And I go to the customer and say, sorry, we are not able to process your payment please try later, or whatever your, you know, the business and product team has decided about the customer journey or to show them something. So in T-Mobile also whenever we do any such thing, we always look out for such scenarios. Because our leadership always have given us one guidance that since T-Mobile also is into retail and care at any given time, our customer should have a talking point.
If I am a rep and you are my customer, you are standing in front of me in the retail store and I’m doing something for you. I cannot keep looking at the screen that it’s doing something. I need to tell you what exactly is happening. So if your payment couldn’t process, we will tell you that payment is not being processed rather than the, you know, the endless spinner of death is coming over and over and over. And then we will also tell you, please try again. And that is where the next pattern, retry pattern come into the picture.
Mario Gerard: So let’s talk a little bit about the retry.
Vidya Agarwal: So retry is self-explanatory as timeout was. In retry pattern what happens is we assume that maybe there is a hiccup on the server, or something didn’t go well. Before I really go to the UI back and failed everything, let me try one more time. So there are multiple ways where you can put retry logic. Let’s just start top down UI. In that case, my call failed to backend. I sent it back to the UI. UI will retry One more time by itself. That is UI is doing it. Other thing is your API can do it. So let’s say you are finding customer information from your customer domain. You are calling their backend system from the API, and now the microservice itself can do the retry because you still have two second, I assume you are keeping one second to take data back from API to UI. Now you still have time. So you will do after every hundred second, maybe two or three retries, or maybe I read 250 millisecond or 500 millisecond, whatever your threshold is. And many times you need to align as I was saying earlier, owning your dependencies you talk to the backend.
Mario Gerard: So you don’t want to unnecessarily inundate their service with 200 calls, which multiplied into two fold or three times you’re retiring. If your retry mechanism is too hot, then you’re kind of killing their service too hard.
Vidya Agarwal: That’s right. So what happened in that case, you need to hold a very small time lag for the hiccup. And then most of the time that service might come back. I have done this pattern in my previous work assignments. And we had that hiccup on the caching server. We were running a cache on a VM and many times we were not able to read from the cache, because VM had a hiccup. So what we did, we got the retry pattern for that. And before we really go, so what happened in case of caching is there is another pattern called cache aside, cache aside pattern means if your cash is not available, you go and read from the backend. So since we knew we had a cache, what we were doing is we were making sure if the system is not available, there is no heartbeat. We are going to retry again. And then delete it. If not, once our retries has been exhausted, we’ll retrieve the retries, every 250 millisecond. If those retries of 750 millisecond has been exhausted, then we go to the backend, read the information, and put it in the cache.
Mario Gerard: You’re saying that the Microservices is making the call actually knows whether it’s hitting the cache or not. Oh, interesting.
Vidya Agarwal: So what happens is you always know where you put the cash. You know where our cash server is, you know how we are defining the key and values of the cash. There is a key value pair. So if you are putting my information, let’s say, and I am your customer, there should be something your key or organization or team is aligning to that. How would you declare the key for this customer? Because there are so many customers. Yeah. And then when will you expire the cash? You cannot hold my information forever. Is it 30 days, Is it one day? Is it just session timeout? So there are multiple ways of holding the cache information. So retry patterns, many times the third way of retry is that even API is not doing it, backend is doing it. So let’s say I am customer domain. I have my database.
How I am giving that information back to you from my database. I also expose the Rest end point to you. Now think about my database system, but there is a hiccup on the database instance and what will I do? Should I start giving you 500 back? And then you implement retry logic because you are the consumer of my API. And you are the provider as a microservice to your UI. So what you do? We talked about UI implementing retry, not a good idea. We talked about microservice, which is consuming backend Microservice. We talked about that. Now the third is before any company or any team, which is heavily dependent on backend systems before they do retry logic, they should always trigger and initiate a conversation with the backend team, do you have a retrial pattern in place?
Mario Gerard: Within your Microservice itself.
Vidya Agarwal: That’s right. So if you are my API consumer, and you want a microservice team for your UI and I am customer information provider to you and my API, you are consuming. Then before you to try or to retry logic, you should ask me, Hey Vidya, does your team have retry logic? So I do not do it. Now when I receive your call, I have a retry logic in place within my microservice that I will hit my database 250 millisecond apart three times before I give you 500, unlike I gave you 500 right away, the moment I received the call, and then you said, oh, I got 500, Let me try one more time. Oh, another 500. Let me try one more time. Ah, now I got 200. So that team can also do it. So there are multiple ways and there is nothing that, which way is better or wrong. The only thing is that these are the ways how somebody can think and where it should you shift the responsibility of it. My recommendation has always been that whichever domain owns it since it’s their product, it’s better to live with the domain. [09:40 inaudible] is really implementing it.
Circuit breakers
Mario Gerard: Got it. Got it. That’s very interesting. Next one was circuit breakers.
Vidya Agarwal: So circuit breaker is a very key thing, and it is becoming very prominent and useful in terms of microservices. Now, again, it is self-explanatory many people might think that circuit breaker they heard in the electronic component. So it’s like exact same thing. Whenever there is some spike in the power and things go and your circuit breaker kicks in and it does the magic. So your electronic component doesn’t go bad. Same thing happens in case of microservices or the APIs. What happens is since in microservice architecture, there are so many moving parts. There are so many small, small services and all these small services. When I say moving part means, think about multiple small, small wheels, which are stuck to each other in those slots and they all are moving together. [10:38 inaudible].
Mario Gerard: Everything has to work for that second needle to go one.
Vidya Agarwal: Exactly. I have the same visual in my mind. So thank you so much for calling it out. And I’m saying it because for the people who are listening. So they have a visual in mind. Now the problem with microservice architecture is if one service fails, then what happens? Or what if my microservice or your microservice or any microservice keep calling another service, which has been constantly failing. In this case, what happened? You are continuously making calls to a service, which has been failing. Means your failure calls has been piling up. In such cases, circuit breaker pattern comes very handy.
There are many open source circuit breaker implementations available. If any team is really looking to implement it, you do not need to hand roll the code for it. Just search on internet. Netflix has [11:32 inaudible] and there are many more available out there on internet, but you can take advantage of. So what it does is, as I said, it is you know, inspired from the electronic component and it does the exact same purpose. And where it is useful is when we have distributed systems, that is what microservice exactly is. And where if you have a repetitive failure, which can lead you towards a snowball effect, then your failure calls are piling up and bring the entire system down.
It’s like a denial of service attack. Think it that way, you’re bombarding a system which is not responding, giving a 500 back and back and back, right. Now in such cases, what do we do? What do we tell our customers back, to our UI or the API consumer? We need to tell them, Hey, you know what? There is something wrong happened and please do not make any further calls. So what do you do? You stop them. So no further calls are coming to your system and you get time to heal. Many systems are supposed to design that they are self-healing, resilient, self-recoverable. While the system is self-recovering, self-healing calls has been stopped. Now circuit breaker also has a mechanism in it that it knows that I can make one call as a [12:43 inaudible] call and see, to test the water if it is successful or not. And there are three states in circuit breaker, one is closed, then open and then half open. When your error starts happening, your circuit breaker is open. Now when it is half open, it can make a call to test the water. And if that call is successful, it will let the other calls go in. And when it sees that the percentage of success causes increasing one after another, it will close it. And that means the traffic can flow as it’s supposed to.
Mario Gerard: Something like a load balancer.
Vidya Agarwal: Load balancer. You can say that. Load balancer also plays a key role in all these things. Many load balancers are very smart these days, they are bringing such capabilities, these different patterns of try, timeout and all these things. They are adopting all these patterns and bringing it within load balancers. So teams has less and less to do when they are coding. There is one more thing I want to tell for the benefit of audiences that when should you trigger circuit breaker and when you should not. So circuit breaker is supposed to be kicked in when you are getting errors, like 500. If you are getting 400, that’s not the right error code.
Mario Gerard: When server is not responding.
Vidya Agarwal: Exactly. Because 400 is more about security and your page not found, your security didn’t go well. So teams need to be cognizant of these sections, error codes and all these things and [14:09 inaudible] HTTP error codes. And to be cognizant of that, do not just think circuit breaker applies to every single error. Then it could be, you know, very massive for teams to triage and fix it. So they need to be cognizant what kind of error, where to put it and then do it right.
Mario Gerard: I was talking to a friend of mine. Like I think more than six months ago, and we were talking about something like a tax service going down. And we were talking like, what would the customer experience look like? Supposing you’re doing something like a black Friday sale, right? You have millions of customers. And one microservice somewhere is stopping to respond. At that point, I think we had this conversation earlier as well. Do we say the order is not processed? Or do we just process the order and eat the tax for that particular order. We can still process the order and then tell the customer, Hey, this is what you’re going to pay without charging them tax. Where the company absorbs the tax, just so that the order is processed. So when multiple microservices are needed to function or to render a final end page, we can also ensure that if a particular microservice is not extremely crucial what the customer end experience is going to be.
Vidya Agarwal: I can give you one real world example. So T-Mobile is always up for the customer journey. We are very customer focused. We did one initiative about the same, almost something similar. Think about it for any retail organization. Their first objective is to collect money from the customer as early as possible. The thing is that that saves customers time. Customer has great experience. Customer got in their hand, whatever they wanted, and they paid the money, and they are out of the store. As you just called out, it was not related to texts, but it was related to payment. We decided we worked on one initiative. We called it manual imprint. Think about it. You’ve walked in a store with your credit card, unlike check or cash. Do not take check, but you take cash in retail stores. You’ve worked in retail store and for some reason, which is very rare to happen. My Ingenico device, payment device and service is down. Even let’s say device is connected. Everything is fine.
Mario Gerard: When you talk about a device, you’re talking about the physical swipe machine which is reading the magnetic part.
Vidya Agarwal: That is fine, but my backend system is not okay for whatever reason. Now what do I do? The customer wants to buy a new iPhone thousand dollars. And would I let the customer go? So what we did? We worked on an initiative where we implemented manual imprint. So manual imprint is that device where you put the slider thing. You put the credit card in, you slide it and then you give them the receipt by hand. Or if you can print the receipt, you fill the information, you print the receipt and then you will fill the information in the UI that how did you do it and then that information be processed back at a later point in time. But because only payment was down, what we did, we completely designed a new UI screen for that. Got it. That is what you were talking that, how would you, I look like you see, and this entire initiative required entire architecture discussion, many, many architects, domains, business, product, wireframe team.
Mario Gerard: Because there’s some risk also there. There is some risk, but you want to have the customer experiences definitely place way above the risk factor that is there
Vidya Agarwal: There is always trade off.
Mario Gerard: There is always trade off.
Vidya Agarwal: There’s a tradeoff. But when we take credit cards and all, we will make sure it’s your credit card and credit identity and all these things happen. But since you mentioned that that how would UI look like I just wanted to bring that at T-Mobile we are very cognizant of such things. We are very customer focused having product mindset. We are always up to cater to the needs of the customer and keep them happy. So we have that initiative and if something like that go [18:16 inaudible] in a way that we cannot recover everything, then how do we do it? Even we did a similar thing for orders. Many times in talking about the domains and bounded contexts, we have a different system altogether to print the receipt. An order is processed, order is fulfilled, the printing of the receipt is a different domain altogether.
Mario Gerard: Different Microservice.
Vidya Agarwal: Different microservice, different domain, different backend. So that publishes the event that goes to their system, that system get the order information, everything, that sends us the information to print the receipt in PDF. So think about it, visualize it. Many people think, oh, that’s too much, but that’s what exactly microservice is. There are so many moving parts. And each part is so independently deployable, it is scalable, secure, and well-designed that when they work together, it works beautifully. So in many cases, talk about the same thing, how user experience will look like. Some cases, what happened is that order got placed. Everything is good, but receipt is not being printed. Then what do we do? I’m standing in front of you in the store. I paid a thousand dollars credit card, worked, everything worked. I said, give me the receipt, you are holding the bag with your iPhone, but you don’t have a receipt. What do you do? So in those cases, we again redesign our UI. If that service fails, our API will tell the UI that service failed and we load a new screen, which gives exact instruction to the retail wrap that please hand write the receipt. And we will take, they will take the bill book out and they will hand write the receipt for you, like the [19:55 inaudible] and fill it. And then what do you need? You need just the proper receptor in your hand. Maybe it’s [20:00 inaudible] print it, that doesn’t matter. And it will also have retry it or whatever. And if even that doesn’t work then, so to answer your question, what you were asking out of curiosity is that, how does it work? At T-Mobile very, we are very cognizant, and it takes a lot of teams to complete that together. And just one single thing like that, so I gave you two examples, real world scenarios. How we fix it.
Mario Gerard: And this is like, when you see so many teams coming together and it’s also then training the sales reps, right? It’s like a… [20:33 inaudible].
Vidya Agarwal: You brought a very good point. [20:34 inaudible] is heavily, you know, by retailer stores. Unlike many of the companies who are only online. Our leadership is still investing a lot and we are, you know, very promising about the retail stores and all. So yes, you are right. We have proper training material available for them [20:52 inaudible] and that, business and product teams drive those initiatives for the training material for them, that in such instances what needs to be done.
Mario Gerard: It’s like so many teams are involved in a small effort when you say, Hey, when your printing system does not work, I want to do this, product manager comes with an idea. Then there are like 10 architects, 30 teams involved. And then you have to market team there. It’s like a pretty huge program when you did something like that.
Vidya Agarwal: And the problem comes in, which I face a lot, many times when I hear it with teams is the timeline. So I’m ready, I am just a UI change and I’m screaming about, I can do it in two weeks, but I am the backend. I cannot do it. Then how do we align with those timelines? And that is where, you know, the new thing, like feature toggles and feature flags and all these things come into the picture because my team has velocity. I’m a UI team. I just need to build another new page for my single page application. And I show that I’m done. I’m not going to wait for you because I have velocity now. So I take it. But I put a feature flag that until this thing is ready, don’t do it. Then in the configuration files you will do is this feature ready and not ready? So my code can go in the pipeline, but it’s not [22:08 inaudible] feature toggle or feature flags.
Bulkheads
Mario Gerard: That’s interesting. The next topic was bulkheads.
Vidya Agarwal: So bulkhead is a very interesting time. So for people to visualize what bulkhead is, if you go to a boat, what do you see as some vertical partitions, which you might think just to sit, which is right, but in the ships, bulkhead came from the ships. In the ships what happened at the bottom? There are proper vertical boxes, like small room sized boxes. And that is so closed, they are not connected to each other. And there are multiple of those. So what bulkhead does, they are designed in ships to prevent the sinking or if water leak happened, that leak happened only in one room or one area. It is Segregation. So why we are segregating it. We are salivating it for the repetition of failure, or the failure cannot occur to the other system.
Mario Gerard: Reducing the impact of that. Only that one component fails. But that failure does not inversely affect the entire ship itself.
Vidya Agarwal: Exactly. So if I want to put it this way, I will say that it is bulkhead pattern, especially in microservice. Architecture is used to avoid faults in one part of a system taking the entire system down. So wherever fault happened, you lock it down and then that’s it. So it doesn’t propagate further. And that it is used mainly to segregate resources. If that fall happened, then what will you do? Your entire may go down. So let me give you one real life example of this, where we applied very recently the bulkhead pattern. For one of the domains services, we already have set of microservices of level. And we were building the new capability, the new capability, let’s say, hypothetically, you have some sort of services, get post, put, delete, whatever. And now in the same microservice, your domain capabilities aligned with the same thing that its billing or payment or whatever, but you are doing a more rigorous or more resource intensive action.
You need to build an API for that. What it could be, for example, think about a bulk processor. You are doing some sort of bulk processing job kind of job. That’s about process, right? So you are processing payments. Let’s say you collected payment the whole day. Microservices going one by one call happening load balancer is diverting it. Your payment is being processed, but since it is payment in the payment capability, you need to put a bulk processor, which will take all the jobs in the last 24 hours and then aggregate it [24:46 inaudible]. Now you happily said, oh, it’s a payment. Let people me put this bulk processor in the payment service itself. I hope everybody can visualize what we are talking here. And I’m giving a real world example, which we solved using bulkhead. Now this is the scenario. Now I talked about bounded context. I only talked about business capabilities and this bulk processing of payment fits in the exact payment microservice. Now what will you do? You are going to write it in the same controller. Where all other Get, Put, Post, Delete, credit card payment processing all happening. Now think about it this way. Now, if this bulk processing thing, takes longer, stuck somewhere [25:26 inaudible].
Mario Gerard: Suppose you’re aggregating a yearly year to date revenue report.
Vidya Agarwal: One parameter changed your entire Container can go down. It means you will contaminate entire container. Then what will happen to the regular business where personnel is coming to the store, slipping the card, collecting payment, making online payment, calling [25:46 inaudible] channel and making payment and all. So what we did, we few folks get into a room together. We discussed the scenario, and we came up with the exact same thing. That if we do it, and there is an issue, it got stuck on one thing. And we did not say, okay, if this entry is failing for whatever reason, skip it or retry it and go to next. What if it is there only, keep retrying, keep retrying, and keep trying.
Mario Gerard: It can flood the system.
Vidya Agarwal: Exactly. And then entire thread will be get logged. Everything is consumed in that container. Then you are bringing the entire payment service down. So what we decided, we said, okay, it is still belongs to payment, but it’s a bulk processing thing. Let’s put it in a separate container. So we have a separate repo where all the bulk processors are. We will put it there, we will name it properly. And then we host it in a separate container. If you are not in a container, maybe VM putting a separately, if you are serverless, put it on a separate process. Whatever you do consider deploying them into separate virtual machine, container, process, Lambda as your function, whatever you have. So that is what exactly the bulkhead is. And I gave you a scenario as well.
Mario Gerard: So the ideas is that you do not let an offline processing system, for example, or a separate processing, which does not, which is not part of the regular live processing, which the customer needs where that’s coming versus something which is doing some heavy work. You kind of segregate it into two separate buckets or two separate microservices almost, which might be in the same domain, but two separate services so that it does not take down live processes.
Vidya Agarwal: Exactly. So if there is a component one which is start hanging and you are building component two, then component one hanging should not impact the functionality of component two. So in such scenarios, people need to be a little bit more cognizant and think a little bit far in advance that what can go wrong with this thing. And when you think about this reactive way and a little bit defensive about your architectural thinking and design patterns and what can go wrong and service availability, because at T-Mobile we also believe in something called always on time. So always on time means that whatever we have is always working, it’s always up and running. So these are very key design principles for architects and all other people who have impact on the technical designs that whatever we design, we think through all these things, and then we really work on it. So I gave you one real example. [28:20 inaudible]
Good practices to monitor your Microservices
Mario Gerard: That’s fantastic. And I think when we talk about patterns and designing Microservices, I think the last thing which we wanted to talk about is how effectively we monitor our microservice applications. And I think with monitoring also comes troubleshooting, right? So how do we generally, what are the good practices to monitor your Microservices?
Vidya Agarwal: For many teams monitoring could be a little bit challenging because what happens, there are so many moving parts. But the beauty is that you do not need to monitor everything. If every microservice team, whichever you are building and owning, you only monitor your stuff. And then there are if you are logging it, for example, it’s Splunk. Then there are different, you can see the traffic going in, light traffic as well. And if in your customer journey, you are making four or five API calls to different domains, you can see what all call fail, what all call becomes successful. But at the end for a proper UI where you are talking to maybe 5, 10 different microservice or domains for you, what matters is whatever API calls are being made, if all your APIs, which is, let’s say 15 API is owned by three teams, means five microservice, each team, right. If all the APIs, are being monitored and you have proper API dashboards. And based on the threshold.
When my API failed, let’s say one in a hundred. That’s okay. But now it’s failing 20 in 100, whatever threshold you are [29:50 inaudible], then you do the, you know, trigger a message in the slack channel. So at T-Mobile we have all these things. So this is another, as I said, we have a principle called always on. We have another thing called work flawlessly. So in order to be always on and work flawlessly, we are very cognizant and aware that whatever we are building, how do we monitor it. So we have various API health dashboards in place where we consistently monitor all the APIs, all the backend systems. And we try to gauge it ahead of time. Even the response time. Even API might not be failing, but the response time is going slow, slow, slow. And that is now an edge that it’s supposed to fail. Maybe servers resources are being consumed.
Mario Gerard: What I’ve seen is normally a latency 95 percentile of your latency is that, you know, you say 200 milliseconds is my benchmark. So if 95% of my calls are below 200 milliseconds, don’t page me. If it goes about 200 milliseconds give me a[30:54 inaudible] that somebody can go and look into what happens. So there’s latency based triggering. Then there’s number of calls. If the number of calls go exponentially high for some reason, there’s a rouge client somewhere, which is making, you know, 200 calls every second, you know, somebody released some third-party app which is making multiple calls, which, you know, increases that. Then you have a CPU utilization goes up for some reason, there’s a memory leak because a new application was deployed or CPU, memory, those kinds of, you know, triggering mechanisms. So there are, I think, various types of monitoring statistics, which, you know, you use to monitor your microservice and all these monitoring you have set organization wide threshold, which you’re trying to set so that we are on call rotation.
Vidya Agarwal: That your application is always up and running.
Mario Gerard: To ensure that the application is always running, you have five or six types of threshold. And then you also organization, you say, Hey, if my memory utilization is too high, give me a [31:58 inaudible] page, right. So you set this up from an organization level, not from a Microservice, microservice level, so that, you know, you have some architects who say, this is a pattern we want to follow for all our Microservice applications. So that each team is not trying to figure out what the right thing is. You try to do a standardized approach to do better monitoring across all your microservices.
Vidya Agarwal: You started just right. And that’s where the organizational culture plays a key role because once you study the standards, every team is supposed to apply those.
Mario Gerard: Yeah. So cool. I think we did a very good job you know, talking about microservices. So thanks for the fantastic conversation. I think we covered a good deal of things for our listeners. Do you have anything to add?
Vidya Agarwal: No, thank you, Mario. Thank you for having me. I hope listeners enjoyed it and they will be benefited with this information. I try to bring a lot of real-world scenario from various organizations I have worked and microservices certainly greatest stuff. If you are not even building it, still try to learn it. It’s fun. It’s not very different from SOA what many people are doing. So again, thank you for having me. I really enjoyed it.
Mario Gerard: Thank you so much. Thank you so much for your time today.
There you go. My friends, this is the end of the three-part microservices podcast recorded with Vidya. I hope you enjoyed listening to the podcast as much as I enjoyed chatting with him. Do stay tuned for more podcasts coming your way.















yes, lot of real-world scenarios, we got it!!